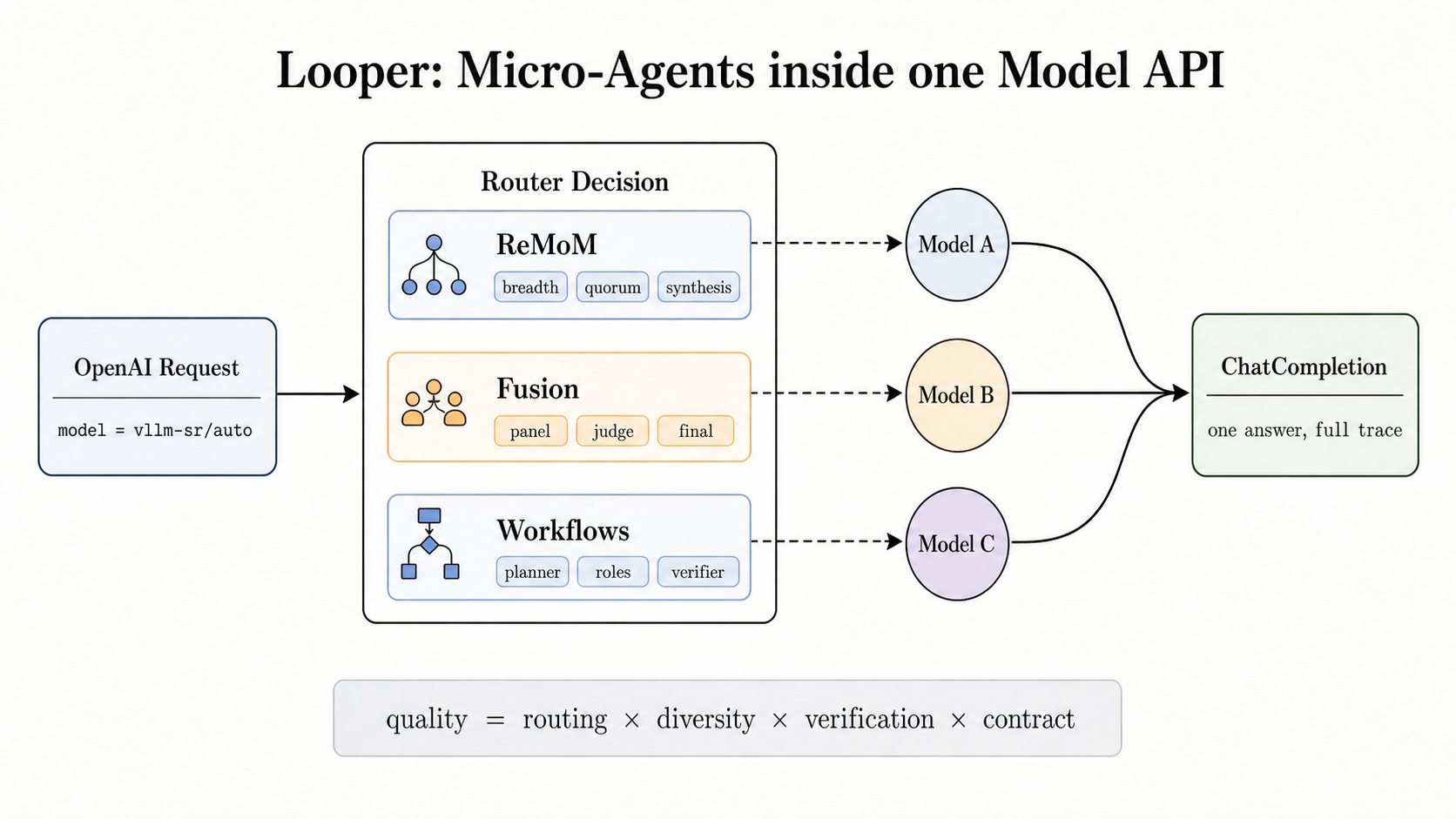
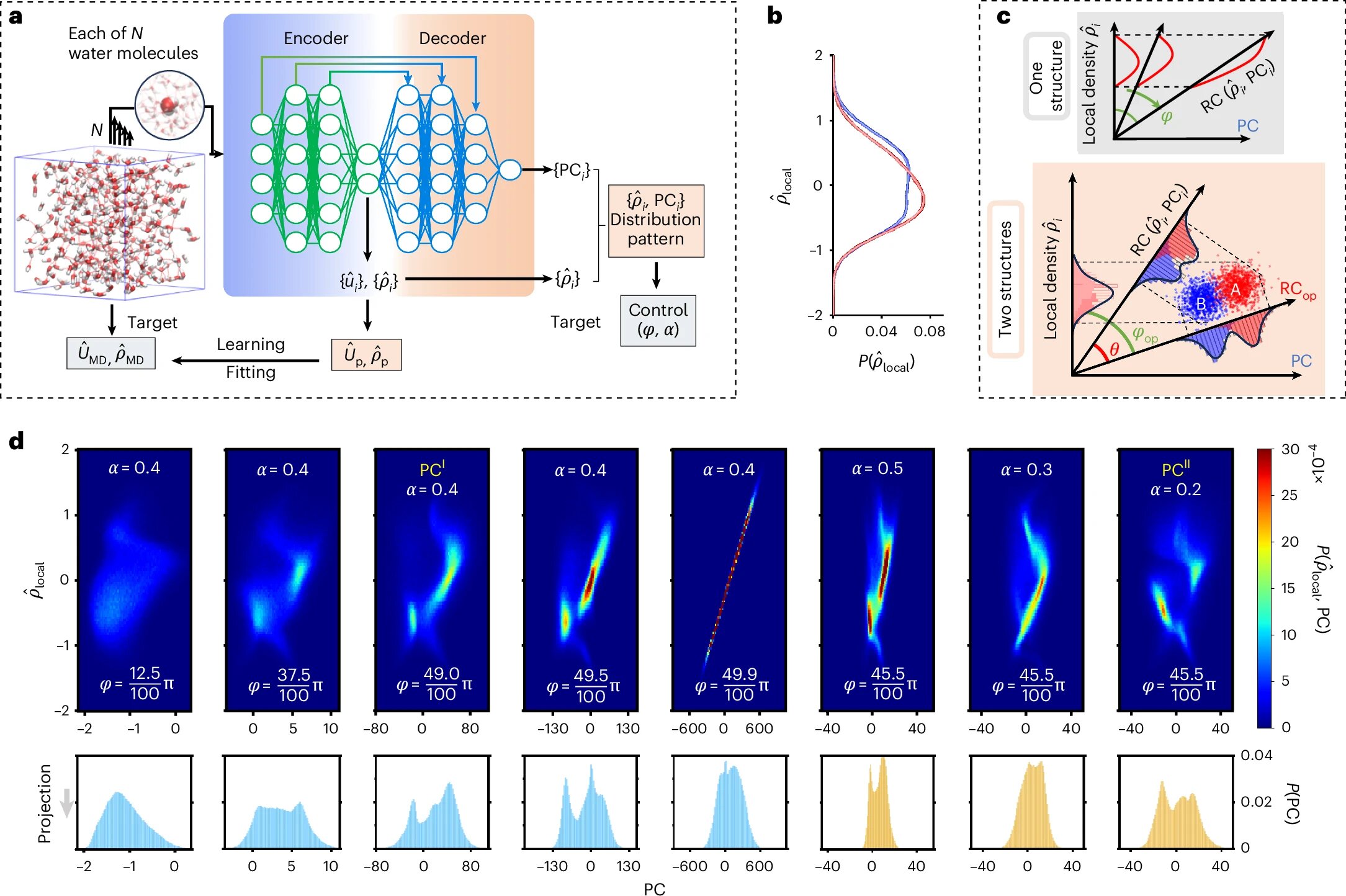
Qwen 3.6 27B is the sweet spot for local development

Qwen 3.6 27B is praised as the optimal local AI model for developers, offering strong general‑intelligence capabilities while remaining runnable on consumer hardware. The author details successful tests—creative writing, code generation (e.g., a hexagonal minesweeper), and multi‑token prediction—using llama.cpp with 8‑bit quantization from Hugging Face, achieving 30‑105 tokens/s on a MacBook Max M5 and 50 tokens/s on an RTX 5090. Benchmarks show it comparable to or slightly outperforming frontier models such as DeepSeek‑V4 Flash and approaching GPT‑5‑level performance. The post argues that locally run models enhance privacy, reduce reliance on costly APIs, and foreshadows a future where even larger open‑weight models like GLM 5.2 become affordable for enterprises.